การโหลดข้อมูล Iris และตรวจสอบเบื้องต้นพื้นฐานสำหรับ Deep Learning
Workshop นี้แสดงการโหลดข้อมูลดอก Iris และตรวจดูเบื้องต้น (Visualization) ซึ่งเป็น ขั้นตอนแรก ๆ ของกระบวนการ Machine Learning, Deep Learning เพื่อตรวจดูลักษณะการกระจายของข้อมูล โดยข้อมูล Irs ทางผู้จัดทำ (Seaborn) ได้เตรียมให้แล้ว เราสามารถใช้ Seabor โหลดจากเน็ตมาได้เลย (ต้องติดตั้ง Seaborn)

import seaborn as sns
import matplotlib.pyplot as plt
df = sns.load_dataset('iris') # โหลดข้อมูลจาก ข้างนอก
df.head()
Code language: Python (python)ตรวจดูว่ามีข้อมูลสูญหายหรือไม่ (Missing Data )
df.head()
Code language: Python (python)df.isnull().sum() #จะพบว่าทุกตัวเป็นศูนย์ หมายถึงไม่มีข้อมูลสูญหาย
Code language: Python (python)สีจุดข้อมูลตามสายพันธุ์ (species) หมายถึง จุดข้อมูลดอกพันธุ์หนึ่งก็ใช้สีหนึ่ง เช่น Setosa สีแดง Virginica สีเขียวsns.set_style('whitegrid')
sns.scatterplot(x='sepal_length',y='sepal_width',data=df, hue='species',palette='Set1', s=70) # v0.12.2
plt.title('Sepal')
plt.show()
Code language: Python (python)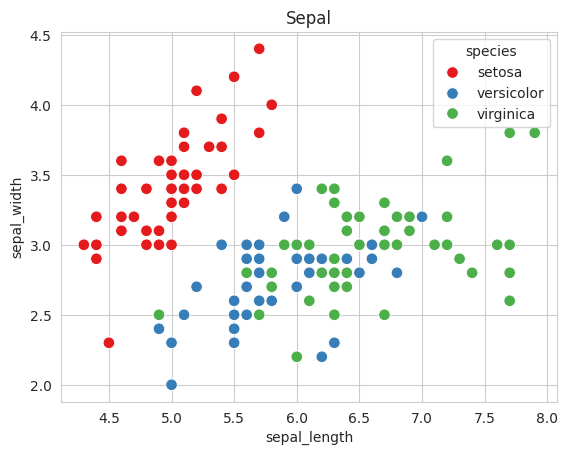
จะพบว่ากลุ่มจุดข้อมูลขนาดกลีบ Sepal ของ Setosa แยกจาก Versicolor และ Virginica อย่างชัดเจน (ดูจากหน้าจอคอมพิวเตอร์จะชัดเจน เพราะแยกสายพันธุ์ด้วยจุดสี) เนื่องจากขนาดของ กลีบดอก Setosa มีขนาดเล็กกว่า
กลุ่มจุดข้อมูลขนาดกลีบ Sepal ของ Versicolor และ Virginica มีการเหลื่อมกันอยู่ เนื่องจากกลีบ Sepal มีขนาดใกล้เคียงกัน
จะเห็นว่า กลุ่มข้อมูลทั้ง 3 สายพันธุ์มีจุดเหลื่อมทับกันเล็กน้อย (ตรงบริเวณเส้นประ) โดยรวมถือว่ามีการแยกชัดเจนระหว่างสายพันธุ์ เมื่อเทียบกับ Sepal ดังนั้นหากจะสร้างระบบ Machine Learning คัดแยกสายพันธุ์ของดอกไม้ ควรใช้ข้อมูล petal length กับ petal width จะดีกว่า sepal Length กับ sepal width เนื่องจากมีการเหลื่อมทับกันน้อยกว่า ความแม่นยำของระบบที่ได้จะมีมากกว่า
โดยทั่วไปเรามักจะดูความสัมพันธ์ของ Features แต่ละคู่ว่ามีความสัมพันธ์กันอย่างไรบ้าง จะสามารถนำมาเป็นเกณฑ์จำแนกหรือคัดแยกได้หรือไม่ คูใดจะสามารถคัดแยกได้ดีที่สุด จากข้อมูล ตัวอย่างนี้ Feature มีเพียง 4 ตัว (4 คอลัมน์) การสั่งพล็อตทีละคู่ก็ใช้เวลาไม่มากเท่าใดนัก แต่ถ้า มูลมี Feature มีหลายตัว ถ้าพล็อตทีละคู่อาจทำให้เสียเวลา เราสามารถลดเวลา โดยสั่งให้พล็อต คู่ได้ในคำสั่งเดียวคือ paiplot ระบบจะพล็อตข้อมูลในลักษณะตารางเมทริกซ์ ดังนี้
sns.scatterplot(x='sepal_length',y='sepal_width',data=df, hue='species') # v0.12.2
plt.show()
Code language: Python (python)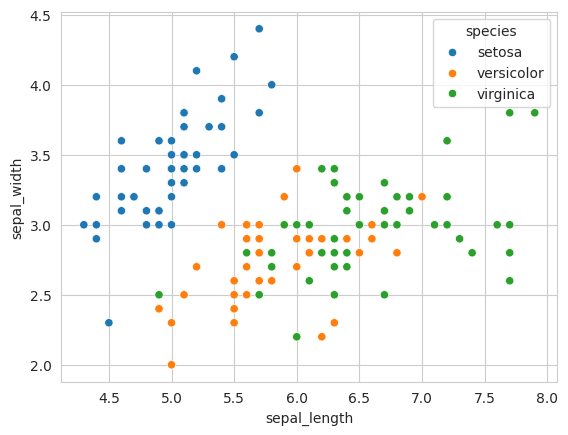
sns.pairplot(df, hue='species', height=2.0)
plt.show()
Code language: Python (python)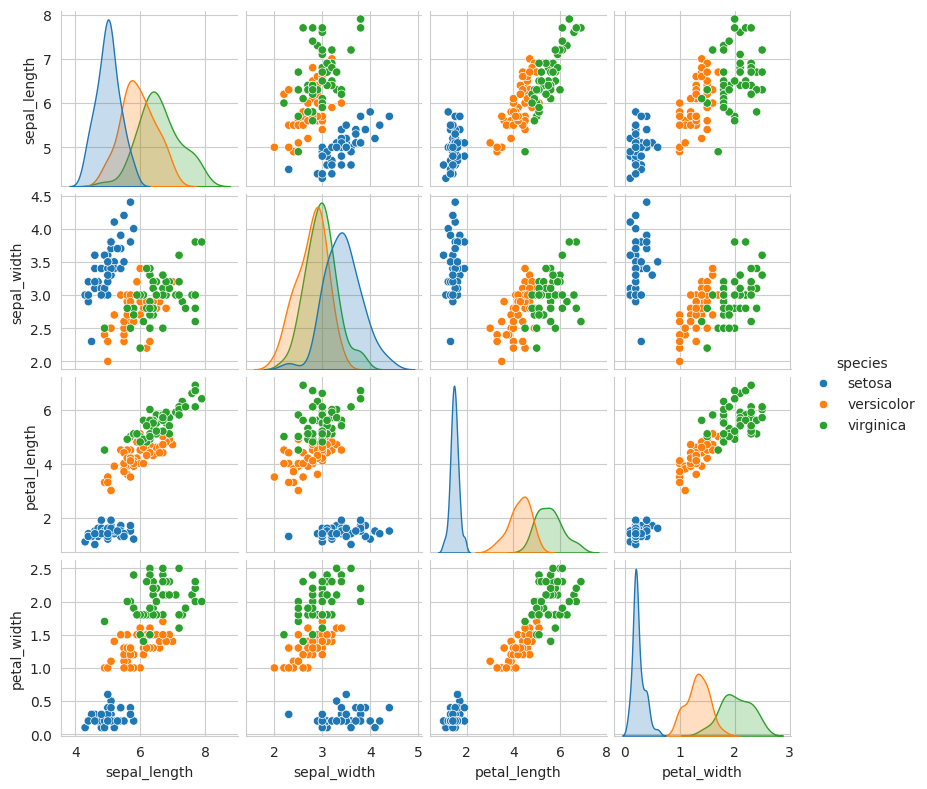
กราฟเส้นโค้ง (คล้ายเส้นภูเขา 3 ลูก) แสดงการแจกแจงความถี่ของกลุ่มข้อมูลแต่ละสายันธุ์ ณ ยอดสูงของภูเขา จะเป็นค่าเฉลี่ยของกลุ่มข้อมูล ฐานของภูเขาแสดงการกระจายของข้อมูลคล้ายๆ กับหลักการของ Normal Curve หรือ Histrogram)
การเลือกดูดอะแกรมให้ลากจากแนวนอนไปหาแนวดิ่ง เช่น petal width ไปหา petal Length ก็จะได้ไดอะแกรม

ทีมงานพร้อมให้คำปรึกษาและพัฒนาซอฟต์แวร์