การเตรียมข้อมูล Feature และ Label สำหรับ Deep Learning
Workshop 2: เตรียมข้อมูล Feature และ Label Workshop นี้แสดงการเตรียมข้อมูล Feature (คุณลักษณะเด่น) และ Label (Class หรือ พันธุ์) ดอก Iris เพื่อใช้ในการ Train และ Test (ทำต่อจาก Workshop 1)
feature_cols = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
X = df[feature_cols]
X.head()
Code language: Python (python)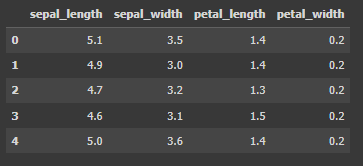
เริ่มจากเตรียมข้อมูลที่จะใช้เป็น Feature หลักการคือแยก Featurer ออกจาก Label ทำได้ 2 วิธีคือ นำข้อมูล df มาตัด (drop) ส่วนที่เป็น species ออกไป ให้เหลือเฉพาะ sepal_Length sepal_width petal_Length และ petal_width เท่านั้น
X = df.drop('species', axis=1)
X.head()
Code language: Python (python)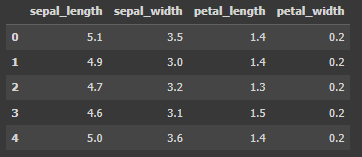
X เป็นเมทริกซ์เก็บข้อมูลทุกดอก (เวกเตอร์ของทุกดอก)
ข้อมูลที่เป็นเมทริกซ์ นิยมใช้ตัวแปรขึ้นต้นด้วยตัวใหญ่
-> คัดเอาเฉพาะคอลัมน์ที่ต้องการเท่านั้น ได้แก่ sepal_length sepal width petal length และ petal width คล้ายๆ กับเลือกก๊อปปี้เฉพาะคอลัมน์ที่ต้องการมาใช้
arrow_upwardarrow_downwardlinkcommenteditdeletemore_vert
ก็จะได้ X เก็บค่า Feature ซึ่งประกอบด้วย 4 คอลัมน์
Label(y)
ก๊อปปี้เฉพาะคอลัมน์ species ออกมา จะได้คอลัมน์ y
y = df.species
y.head()
Code language: Python (python)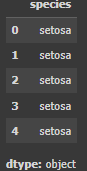
ตรวจสอบมิติ x,y
X.shape
Code language: Python (python)จะได้ (150,4) คือ 150 แถว 4 คอลัมน์
y.shape
Code language: Python (python)จะได้ (150,) คือ 150 แถว 1 คอลัมน์ (จำนวนแถวของ X,y จะต้องเท่ากัน)
X และ y สามารถนำไปแบ่งเพื่อทำการ Train และ Test ต่อไป