ทำ Deep Learning ง่าย ๆ บน Google Colab
ก่อนอื่น มาทำความรู้จักร Deep learning กันก่อน
Deep Learning คือวิธีการเรียนรู้แบบอัตโนมัติด้วยการ เลียนแบบการทำงานของโครงข่ายประสาทของมนุษย์ (Neurons) โดยนำระบบโครงข่ายประสาท (Neural Network) มาซ้อนกัน หลายชั้น (Layer) และทำการเรียนรู้ข้อมูลตัวอย่าง ซึ่งข้อมูล ดังกล่าวจะถูกนำไปใช้ในการตรวจจับรูปแบบ (Pattern) หรือจัด หมวดหมู่ข้อมูล (Classify the Data) อ่านเพิ่มเติม.
Colab คืออะไร
Colab คือ Google Colab ชื่อเต็มคือ Google Colaboratory เป็นบริการ Software as a Service (Saas) โฮสต์โปรแกรม Jupyter Notebook บน Cloud จาก Google
Google Colab ใช้ยังไง เราสามารถใช้ Google Colab สร้าง Notebook เขียนโปรแกรมภาษา Python ได้ฟรี ๆ และแถมยังมี GPU, TPU ให้เราได้ใช้ฟรีอีก ทีละ 12 ชั่วโมง ใจดีสุด ๆ
ขณะนี้ Google Colab มี GPU ให้เราใช้ ดังนี้
- Nvidia Tesla K80
- Nvidia Tesla T4
- Nvidia Tesla P100 (ดีสุด)
โดยเราสามารถ เช็คสเปคของ GPU ได้ด้วยคำสั่ง !nvidia-smi ถ้าไม่พอใจสามารถ เลือกเมนู Runtime / Factory reset runtime เพื่อเปลี่ยนเครื่อง อาจจะได้ GPU ที่ดีขึ้น ถ้ามีเครื่องว่าง
เริ่มต้นการใช้งาน Google Colab
เราสามารถเข้าไปใช้ Colab ได้ที่ https://colab.research.google.com/ จากนั้นก็เลือก NEW NOTEBOOK เพื่อเริ่มต้นไฟล์ใหม่
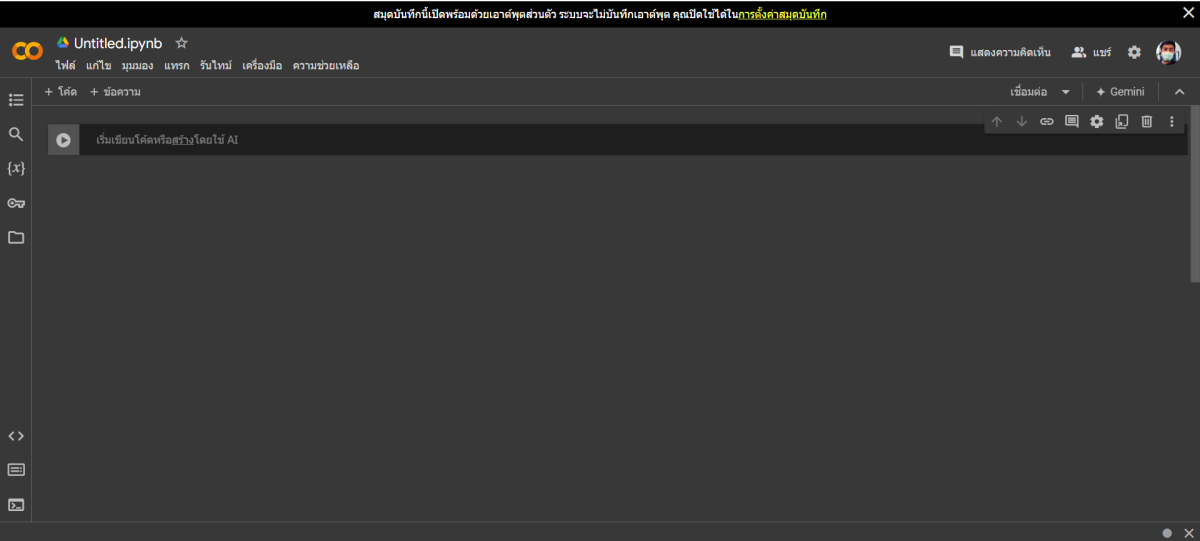
ลองสั่งคำสั่งง่าย ๆ ก่อน เช่น print(“hi”) //Google Colab จะใช้ภาษา python
ช่องสี่เหลี่ยมที่เราจะใช้วางโค้ดเพื่อรันเนี่ย เรียกว่า cell ซึ่งเราสามารถเพิ่มได้โดยกด [+ Code] หรือ [+ Text] ตามในรูป
หรือกดจากที่แท็บด้านบนก็ได้ และสามารถกดรัน Cell นั้น ๆ ได้ที่ปุ่มรูปสามเหลี่ยมที่อยู่ส่วนหัวของ Cell ตามรูปด้านล่าง
ที่แต่ละ cell ก็จะมีเครื่องมือให้เลือกใช้ เรียงจากซ้ายไปขวาคือ สลับ Cell ขึ้นไปด้านบน, สลับ Cell ลงด้านล่าง, link to cell, comment, Setting, Mirror cell in Tab, Delete Cell
ทางด้านซ้ายก็จะมีเครื่องมือที่น่าสนใจอีกอย่างคือ Table of contents เวลาที่เรามีโค้ดเยอะ ๆ เราก็สามารถรวม code ส่วนย่อยเป็น 1 section ได้เพื่อความสะดวกในการหา
ส่วนที่เป็นรูปแฟ้มก็คือเราสามารถสร้าง Floder เก็บพวก Code หรือว่า Data ไว้ที่ส่วนนี้ เพื่อความสะดวกในการเรียกใช้
อีกอย่างที่ส่วนตัวมองว่าใช้บ่อยคือแท็บเครื่องมือ Runtime

ซึ่งสะดวกต่อการใช้งานมาก บางทีเราต้องการรันทีเดียวทุก cell เราก็ไม่ต้องเสียเวลากดทีละอัน
**เราสามารถใช้ทางลัด Shift + Enter เพื่อรันแต่ละ Cell ได้นะ
นอกจากนี้ ด้วยความที่ Google Colab เป็นของ Google เราก็สามารถเรียกของจาก Google Drive ของเราออกมาได้ด้วย โดยใช้คำสั่ง
from google.colab import drive
drive.mount(‘/content/drive’)

ตรงนี้ เราต้องอนุญาตให้สมุดบันทึกเข้าถึงไฟล์ใน Google ไดรฟ์
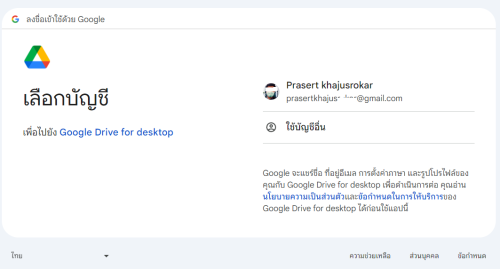
เลือก Email Google ไดรฟ์ ของเรา(ที่เก็บไฟล์ข้อมูลของเรา)
เมื่อเชื่มต่อเสร็จจะขึ้น Mounted at /content/drive
โดยกดตามลิงค์ที่เขาให้มาเราก็จะได้รหัสผ่าน แล้วก็นำมาใส่ในช่องว่างนั้น ดูเพิ่มเติม
แล้วเราสามารถเลือกได้ว่าจะใช้ CPU GPU หรือ TPU โดยกดไปที่ Runtime -> Change runtime type แล้วก็จะได้ pop-up ดังรูปด้านล่าง
ในเรื่องของความแตกต่างนั้น CPU จะถูกสร้างมาให้สามารถทำงานได้หลากหลายกว่า GPU กล่าวคือ GPU จะทำงานในส่วนของการ render graphics หรืองานที่เป็น parallel และในตัวของ CPU จะมี Core น้อยกว่า (4–8 cores) แต่ GPU จะมี Core เยอะกว่ามาก
นอกจากนั้นยังมีการคำนวณที่ต่างกันคือ CPU จะประมวลผลแบบ 1*1 data แต่ GPU จะประมวลผลแบบ 1*n data ทำให้สามารถทำงานได้เร็ว ดังรูปด้านล่าง
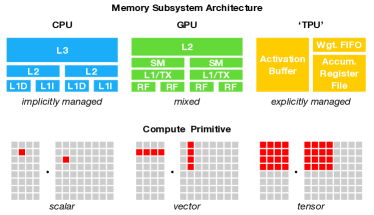
ส่วน TPU คือตัวที่สร้างมาเพื่อการคำนวณขนาดใหญ่ ประมวลผลแบบ n*n data เพื่อทำให้การทำงานด้วย Tensor Flow เร็วขึ้น
โปรแกรม
ในส่วนของโปรแกรมนั้นจะเป็นโจทย์ Boston Housing ของ Kaggle ซึ่งในจะยกตัวอย่างจากการสอนของอาจารย์ MIT ชื่อ Lex Fridman
โจทย์คือให้เราทำนายราคาบ้านซึ่งจากชุดข้อมูลจะเป็นตัวที่มีชื่อว่า medv โดยการนำ 13 ปัจจัยที่เหลือมาเป็น Input
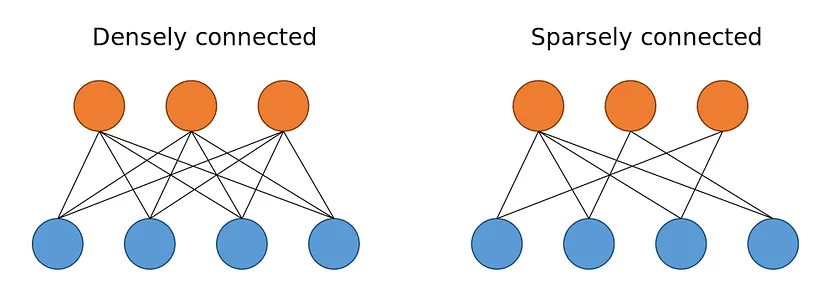
จากตัวอย่างจะใช้เป็น Feed Forward Neural Networks ในการทำนาย และแต่ละ Neural จะมีการเชื่อมกันแบบ dense (fully connected) เพราะว่าเราต้องการใช้ทั้ง 13 ปัจจัยในการทำนาย ถ้าอีกแบบนึงจะเรียกว่า Sparse Neural Network ตือแต่ละ node จะไม่ได้เชื่อมถึงกันหมดตามภาพด้านล่าง
เริ่มแรกสุดให้เลือก Import เครื่องมือตามนี้
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense
import numpy as np
import os
import sys
import pandas as pd
เราก็จะทำการโหลดข้อมูลด้วยคำสั่ง load_data() แล้วแบ่งออกเป็น train data และ test data
ในส่วนของ train_features จะเป็นข้อมูลของ 13 ปัจจัยที่จะเอาไปเป็น input ของ model ส่วน train_labels คือค่าของ medv ที่เอามาเป็นตัวอย่างในการสอน ฝั่งของ test ก็เหมือนกันแต่เป็นข้อมูลที่เอาไว้ทดสอบโมเดล
(train_features, train_labels), (test_features, test_labels) = keras.datasets.boston_housing.load_data()
train_mean = np.mean(train_features, axis=0)
train_std = np.std(train_features, axis=0)
train_features = (train_features – train_mean) / train_std
- คำสั่งสร้างโมเดล
จากโค้ดด้านล่างคือเราจะกำหนดว่ามี 1 hidden layer จาก 20 neuron ตรงนี้เราก็สามารถปรับได้
ส่วน Dense คือการบอกว่าเป็น Fully Connected หรือ การเชื่อมที่ทุก Node ในชั้นหนึ่งเชื่อมไปยังอีกชั้นหนึ่ง
และเราก็จะคำนวณค่า error ของโมเดลด้วย Loss Function โดยจะคิดจาก MSE (Mean Squared Error) โดยการเทรนแต่ละครั้งจะมีเป้าหมายเพื่อลดค่า Loss Function นี้ให้น้อยที่สุดเพื่อให้ได้โมเดลทำนายที่ดี
ตรงส่วน Matrics คือเราจะใช้เพื่อประเมินคุณภาพของโมเดล โดยในที่นี้ใช้ MAE (Mean Absolute Error) กับ MSE (Mean Square Error) ซึ่งแต่ละตัวมีผลที่ต่างกันขึ้นกับลักษณะของข้อมูล
def build_model():
model = keras.Sequential([Dense(20, activation=tf.nn.relu, input_shape=[len(train_features[0])]), Dense(1)])
model.compile(optimizer=tf.optimizers.Adam(), loss=’mse’,metrics=[‘mae’, ‘mse’])
return model
- คำสั่ง Train Model
ในส่วนนี้เราก็จะมีการกำหนด epoch หรือก็คือจำนวนรอบในการเทรน ยิ่งเทรนเยอะมันก็เหมือนโมเดลเราจะมีโอกาสเก่งขึ้น มีความถูกต้องมากขึ้น แต่ใช้เวลานานขึ้นเช่นกัน
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print(”)
print(‘.’, end=”)
import time
start = time.time()
model = build_model()
early_stop = keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=50)
history = model.fit(train_features, train_labels, epochs=1000, verbose=0, validation_split = 0.1,
callbacks=[early_stop, PrintDot()])
hist = pd.DataFrame(history.history)
hist[‘epoch’] = history.epoch
stop = time.time()
rmse_final = np.sqrt(float(hist[‘val_mse’].tail(1)))
print()
print(‘RMSE: {}’.format(round(rmse_final, 3)))
print(‘time:’, stop-start)
จากโค้ดด้านบนจะเห็นได้ว่าเราใส่ฟังก์ชั่น time เอาไว้เพื่อวัดเวลา สำหรับคนที่ต้องการลองรันในหน่วยประมวลผลต่าง ๆ ก็ใช้วิธีการเปลี่ยน Hardware แบบที่ได้กล่าวไปในตอนต้น ส่วนที่เราลองรันก็จะได้ผลดังนี้
CPU ได้ 58.375
GPU ได้ 37.160
TPU ได้ 27.527
จะเห็นได้ว่าลำดับความเร็วจะเรียงดังนี้ TPU GPU และ CPU
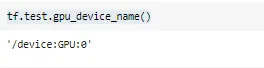
สำหรับใครที่ลองรันด้วย GPU แล้วสงสัยว่าตอนนี้โปรแกรมเรารันด้วย GPU จริงมั้ย สามารถทดสอบได้ด้วยการใช้คำสั่ง
tf.test.gpu_device_name()
ซึ่งจะได้ผลดังนี้ถ้าเราใช้ GPU
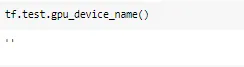
แต่ถ้ายังไม่ใช้ GPU จะขึ้นเป็น String ว่าง (‘ ’)
- คำสั่งดูค่า RMSE
ถ้าค่า RMSE เยอะแสดงว่าโมเดลทำนายไม่ค่อยดี เช่น ถ้าได้ RMSE 5.14 หมายความว่าโมเดลจะทำนาย +- 5.14 ที่ใช้ RMSE เพราะว่าจะทำให้เราตีความได้ง่ายกว่า MSE (RMSE คือนำ MSE ซึ่งอยู่ในรูปยกกำลังสองมาถอดรูท ทำให้ได้ค่าแบบไม่ยกกำลังสอง)
test_features_norm = (test_features – train_mean) / train_std
mse, _, _ = model.evaluate(test_features_norm, test_labels)
rmse = np.sqrt(mse)
print(‘Root Mean Square Error on test set: {}’.format(round(rmse, 3)))
สำหรับใครที่ต้องการการรันที่เร็วขึ้นก็ยังมี Google Colab Pro อีกด้วย ซึ่งเป็นแบบที่เราต้องเสียเงินรายเดือน ราคา ณ ตอนที่เขียนบทความคือ 321.00/เดือน ( $10/month) ความพิเศษของ Pro คืออะไร
- Faster GPUs : ได้ GPU ที่เร็วขึ้น T4 หรือP100 GPU ซึ่งแบบธรรมดาจะใช้ K80 GPU
- More memory: สามารถใช้ High-RAM ได้
- Longer runtimes: คือปกติ Colab จะมีการตั้ง Reset หลังจากช่วงเวลานึงแต่แบบ Pro จะได้ช่วงเวลา runtime ที่มากกว่าแบบปกติถึง 2 เท่า
โดยส่วนตัวแล้วคิดว่าถ้าไม่ใช่คนที่ทำงาน หรือ เรียนที่ต้องรันด้วยข้อมูลขนาดใหญ่มาก ๆ แบบต้องใช้เวลารันเป็นวัน การใช ้Pro อาจไม่ได้ช่วยอะไรมาก น่าจะช่วยแค่เรื่องความเร็วที่เพิ่มมากขึ้นเฉย ๆ แต่ถ้าต้องการความเร็วในการรัน หรือต้องใช้พื้นที่จัดเก็บข้อมูลเยอะ ต้องใช้เวลารันนาน การใช้ Pro ก็ค่อนข้างเป็นทางเลือกที่ดี
อย่างไรก็ตามการตัดสินใจใช้งาน Colab ว่าจะใช้แบบไหนก็ลองตัดสินใจกันนะคะ โดยอาจอ่านข้อมูลเพิ่มเติมได้จากลิงค์นี้ เขาค่อนข้างสรุปมาให้ชัดเจน แล้วยังมี Visualization ให้ดูง่ายขึ้นอีกด้วย
Future work
- เราสามารถใช้ GPU เข้าไปช่วยในทุกโปรแกรมเลยหรือเปล่า
- คำสั่งอื่น ๆ สำหรับการเขียนโปรแกรม
ซึ่งถ้าได้ทำการศึกษาเพิ่มแล้วก็จะมาอัพเดทเนื้อหาให้