การแบ่งข้อมูลสำหรับ Train – Test และ สร้าง Model ประเมินทดสอบสำหรับ Deep Learning
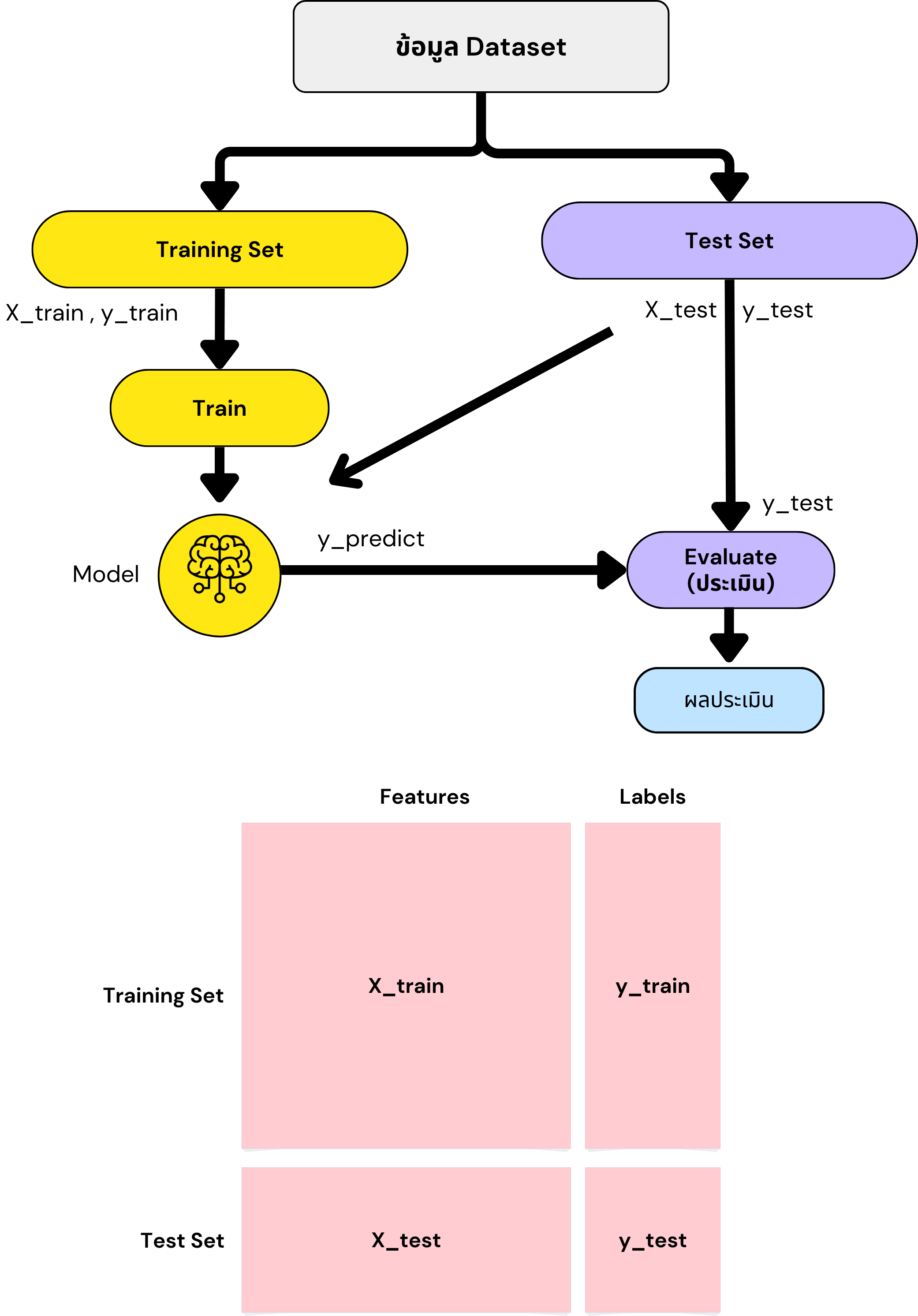
เพื่อการ Train และทดสอบ (Test) จะแบ่งข้อมูลหรือ Dataset ที่มีทั้งหมด ออกเป็น 2 ชุด เป็นางน้อย คือ Train และ Test (ไม่ควรนำข้อมูลที่ใช้ Train มาเป็นตัวประเมินทดสอบ Test)
- ส่วนที่นำไป Train เรียกว่า Training set
- ส่วนที่นำไปประเมินทดสอบ เรียกว่า Test set
ลักษณะการแบ่งจะใช้วิธีการสุ่ม สัดส่วนในการแบ่งก็ขึ้นอยู่กับจำนวน Dataset ที่มีส่วนใหญ่ จะแบ่งสัดส่วน 75:25% หรือ 70:30% หรือ 80:20 ฯลฯ
- X_train คือข้อมูล Feature/input/variables/attributes. ที่แบ่งออกมา ใช้สำหรับการ Train
- y_train คือ Label ของ X_train (บอกว่าเป็นดอกชนิดอะไร)
- X_test คือข้อมูล Feature/input/variables/attributes.. เหมือนๆ กับ X ปกติที่ได้แต่ X test แบ่งออกมาเพื่อใช้เป็นตัวประเมินทดสอบ
- Y_test คือ Label ของ X_test (y_test คือค่า Label ของจริง)
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
Code language: Python (python)นำข้อมูลจาก Workshop ที่ผ่านมา (X,y) มาแบ่งเป็น Train และ Test ตัวอย่างนี้กำหนด สัดส่วน Test เป็น 30%
X_train, X_test,y_train,y_test = train_test_split(X, y, test_size=0.3)
Code language: Python (python)ตรวจสอบดูจำนวน Test set ว่ามีจำนวนสายพันธุ์อย่างละเท่าใด
import numpy as np
(label, count) = np.unique(y_test , return_counts=True)
freq = np.asarray((label, count)).T
print(freq)
Code language: Python (python)จะได้จำนวน y test ที่แบ่งไปทดสอบ (ท่านอาจได้แตกต่างจากนี้ เนื่องจากเป็นการสุ่ม)
ขั้นตอนการ Train
- นำ X_train, y_train ไปทำการสอน หรือ Train ให้ระบบหรือ Model
ขั้นตอนการประเมินทดสอบ
- นำ Xtest ไปเป็น Input ให้ระบบหรือ Model ทำนาย Model จะได้ผลลัพธ์การทำนาย คือ y_predict หรือย่อๆ ว่า y_pred หรือ y_hat
- นำ y_predict หรือ y_pred ไปประเมินเทียบกับ y_test (ของจริง)
ในกรณีที่มีข้อมูลจำนวนมาก อาจแบ่งเป็น 3 ชุด คือ
- ส่วนที่นำไป Train เรียกว่า Training set
- ส่วนที่นำไปประเมินขณะ Train เรียกว่า Validation set
- ส่วนที่นำไปประเมินทดสอบสุดท้าย เรียกว่า Test set
การสร้าง Model และประเมินทดสอบ
Workshop นี้แสดงการสร้าง Machine Learning อัลกอริทีมที่ใช้คือ SYM ระบบจำแนก lris ว่าเป็นดอกไม้สายพันธุ์อะไร โดยทำการ Train และ Test ทดสอบ Model
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
Code language: Python (python)ทำการ Train เพื่อสอนให้ Model เรียนรู้จากข้อมูล Train set ทั้งหมด (X_train) คล้ายกับในการสอนว่า ดอกขนาด … คือดอกอะไร .. โดยทำการสอนไปจนครบทุกดอก (ข้อมูลขนาดดอกคือ เวกเตอร์)
from sklearn.svm import SVC
model = SVC(kernel='linear')
model.fit(X_train, y_train)
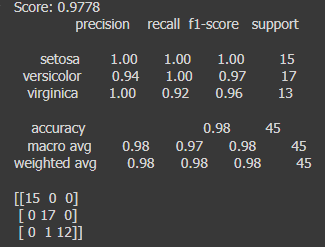
Code language: Python (python)เสร็จแล้ว ทำการทดสอบ Model โดยนำข้อมูล Test set ที่แบ่งไว้ก่อนหน้านี้ เป็น Input กับ Model แล้วเปรียบเทียบกับค่าของจริง ว่าผลการ Predict ถูกต้องหรือไม่ คำนวณผลรวมมีตแม่นยำกี่เปอร์เซนต์ และดูผลประเมินในลักษณะรายงาน Confusion Matrix
y_pred = model.predict(X_test)
print('Score: {:.4f}' . format(accuracy_score(y_test, y_pred)))
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
Code language: Python (python)