การเริ่มต้น Reinforcement Learning ง่ายๆ
การเรียนรู้เสริมกำลัง (Reinforcement Learning) เป็นหนึ่งในวิธีการที่น่าสนใจในโลกของปัญญาประดิษฐ์ (AI) ซึ่งช่วยให้ AI สามารถเรียนรู้ผ่านการลองผิดลองถูก ในบทความนี้ เราจะพาคุณไปรู้จักกับ Q-Learning และนำไปสร้าง AI ที่สามารถเล่นเกม FrozenLake จาก OpenAI Gym ได้อย่างง่ายดาย
1. Reinforcement Learning และ Q-Learning คืออะไร?
Reinforcement Learning เป็นการเรียนรู้ที่ AI ต้องทำการตัดสินใจโดยพิจารณาผลลัพธ์จากการกระทำในแต่ละสถานการณ์ โดยมีเป้าหมายเพื่อให้ได้ “รางวัล” มากที่สุดในระยะยาว ซึ่ง AI จะเรียนรู้จากประสบการณ์ที่เกิดขึ้น
Q-Learning เป็นอัลกอริทึมหนึ่งใน Reinforcement Learning ซึ่งใช้ Q-table เพื่อเก็บค่าคะแนน (รางวัล) สำหรับการกระทำ (action) ในแต่ละสถานะ (state) แล้วใช้ค่าที่เก็บนี้เพื่อเลือกการกระทำที่เหมาะสมที่สุดในอนาคต
2. เป้าหมายของโปรเจกต์
เราจะสร้าง AI ที่สามารถเล่นเกม FrozenLake ได้โดย:
- AI จะต้องหาทางเดินไปถึงเป้าหมายโดยหลีกเลี่ยงหลุม
- ใช้ Q-Learning ในการเรียนรู้วิธีการตัดสินใจในแต่ละสถานการณ์
3. การเตรียมความพร้อม
ติดตั้งไลบรารีที่จำเป็น
ก่อนเริ่มต้น ให้ติดตั้งไลบรารีที่ใช้ในโปรเจกต์นี้:
pip install gym numpy
4. เขียนโค้ด AI ด้วย Q-Learning
ด้านล่างนี้คือโค้ด Python ที่ใช้สร้าง AI เพื่อเล่นเกม FrozenLake:
import numpy as np
import gym
# สร้าง environment "FrozenLake-v1"
env = gym.make("FrozenLake-v1", is_slippery=True) # ใช้ environment ที่มีโอกาสลื่น
n_states = env.observation_space.n # จำนวน states
n_actions = env.action_space.n # จำนวน actions
# ตั้งค่าไฮเปอร์พารามิเตอร์
alpha = 0.1 # Learning rate
gamma = 0.99 # Discount factor
epsilon = 1.0 # Exploration rate
epsilon_decay = 0.995
min_epsilon = 0.01
episodes = 1000
# สร้าง Q-table
q_table = np.zeros((n_states, n_actions))
# ฟังก์ชันเลือก action (epsilon-greedy)
def choose_action(state):
if np.random.rand() < epsilon:
return env.action_space.sample() # เลือกแบบสุ่ม
else:
return np.argmax(q_table[state, :]) # เลือก action ที่มีค่ารางวัลสูงสุด
# การเทรน Q-Learning
for episode in range(episodes):
state = env.reset()[0] # รีเซ็ต environment และรับ state แรก
done = False
total_reward = 0
while not done:
action = choose_action(state)
next_state, reward, done, _, _ = env.step(action)
# อัปเดต Q-value
q_table[state, action] = q_table[state, action] + alpha * (
reward + gamma * np.max(q_table[next_state, :]) - q_table[state, action]
)
state = next_state
total_reward += reward
# ลด epsilon หลังแต่ละ episode
epsilon = max(min_epsilon, epsilon * epsilon_decay)
if (episode + 1) % 100 == 0:
print(f"Episode {episode + 1}: Total Reward = {total_reward}")
# ทดสอบโมเดล
print("\nTesting trained Q-table...")
test_episodes = 5
for episode in range(test_episodes):
state = env.reset()[0]
done = False
print(f"\nTest Episode {episode + 1}:")
while not done:
env.render() # แสดง environment
action = np.argmax(q_table[state, :]) # เลือก action ที่ดีที่สุด
next_state, reward, done, _, _ = env.step(action)
state = next_state
if done:
if reward > 0:
print("Reached the goal!")
else:
print("Fell into a hole!")
env.close()
Code language: PHP (php)5. อธิบายโค้ด
- Environment:
- เราใช้
FrozenLake-v1ซึ่งเป็นเกมที่ผู้เล่นต้องหาทางเดินไปยังเป้าหมายโดยหลีกเลี่ยงหลุมและพื้นที่ลื่น
- เราใช้
- Q-Table:
- ใช้ Q-table (
q_table) เพื่อเก็บค่ารางวัลที่เกี่ยวข้องกับ state-action pair
- ใช้ Q-table (
- Epsilon-Greedy:
- ใช้กลยุทธ์ epsilon-greedy เพื่อให้ AI มีโอกาสสำรวจการกระทำใหม่ๆ แทนที่จะเลือกแต่การกระทำที่ดีที่สุดเสมอ
- Training:
- อัปเดต Q-value โดยใช้สูตร Q-Learning และลดค่า epsilon เรื่อยๆ เพื่อเน้นการใช้ความรู้ที่เรียนมา
- Testing:
- หลังจากการฝึก AI จะสามารถตัดสินใจได้ดีขึ้นและหาทางไปถึงเป้าหมายได้สำเร็จบ่อยขึ้น
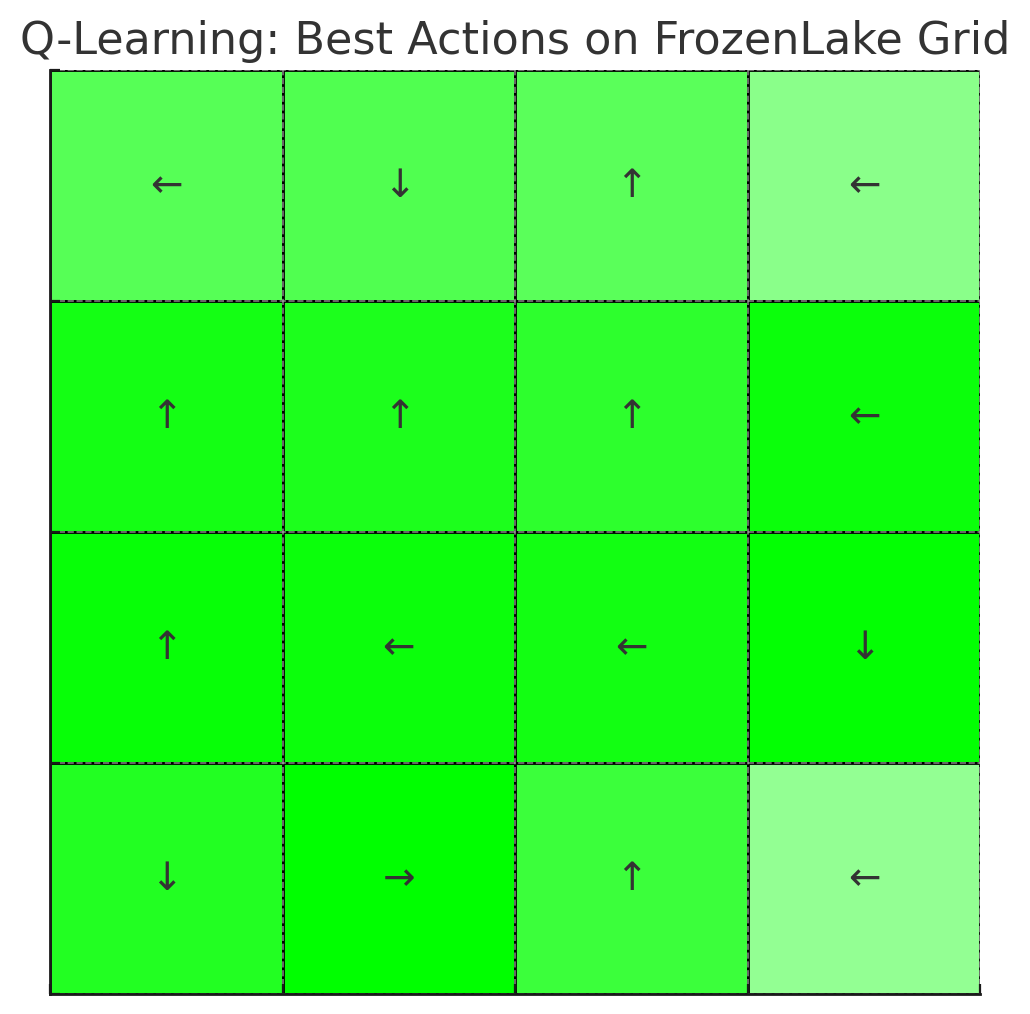
6. ผลลัพธ์
- หลังการเทรน AI จะเรียนรู้วิธีการเดินในเกม FrozenLake และเลือกเส้นทางที่ดีที่สุดเพื่อลดโอกาสตกหลุม
- ในการทดสอบ คุณจะเห็นว่า AI สามารถเดินไปถึงเป้าหมายได้อย่างมีประสิทธิภาพ
7. ข้อสรุป
Q-Learning เป็นจุดเริ่มต้นที่ยอดเยี่ยมในการเรียนรู้เกี่ยวกับ Reinforcement Learning หากคุณเข้าใจพื้นฐานนี้ คุณสามารถต่อยอดไปยังการสร้างโมเดลที่ซับซ้อนมากขึ้น เช่น การเล่นเกมที่ซับซ้อน หรือการสร้าง AI ที่สามารถแก้ปัญหาในโลกแห่งความเป็นจริงได้!
หวังว่าบทความนี้จะช่วยให้คุณเข้าใจ Q-Learning และเริ่มต้นการพัฒนา AI ของคุณได้ง่ายขึ้น ลองนำไปปรับใช้และสนุกกับการเรียนรู้!